Build, deploy and optimize customer conversational chat agents. Monitor use, quality & engagement analytics to optimize value
Automatic Customer Memory & Knowledge Graphs
Learn about your customers through their conversations, and inject that context into their next interaction so customers feel "remembered"
Safety & Compliance
Protect you brand. Redact/Tokenize PII data, Block toxic prompts, and call logging. Auto inject brand and policy instructions.
Secure MCP/Tool Calling & Firewall
Use, Monitor and block un-authorized MCP Server and Tool calls within your enterprise, website or apps.
"Smart" Routing LLM Gateway & Caching Platform
Route requests to the right LLM (and operational) provider and model based on prompt complexity & sensitivity or data tenancy (EU).
Usage Based Billing / Limits for YOUR applications
Configure usage tiers that track your customers' usage, and give them an "A.I. Use," "Call History," & "Overages" page using our configurable embeddable widgets in your app.
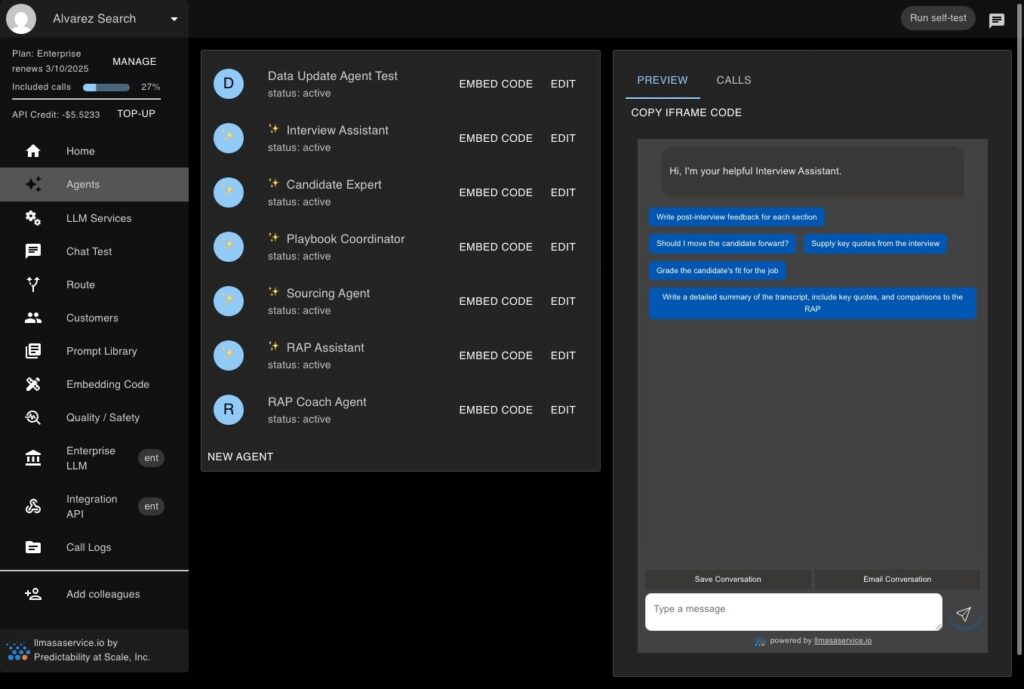
No Code, Low Code or All Code
Secure & reliable streaming agents built for your needs.
Agentic: Scheduled or Event Triggered
At regular intervals or on an event (Customers first call, conversation ended, etc.), another automated Agent can perform analysis or notification work, and so on...
Supporting models from all the major vendors (including self-hosted models)...
Enable usage-based billing in your apps
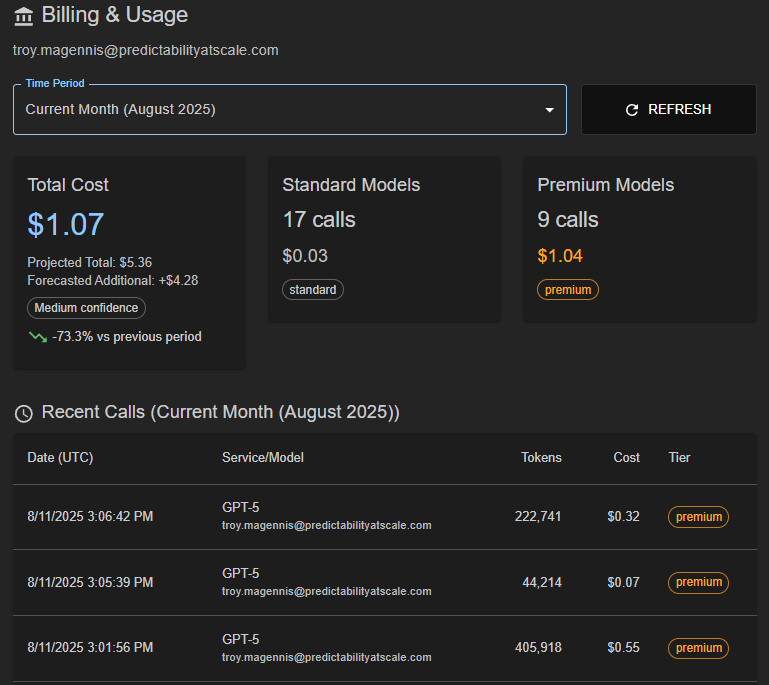
AI Usage-based Billing for YOUR apps
Create multiple usage tiers for call and token allocation on a schedule you choose. Configure call and token limits across four different model strengths allowing customers to use the right power models when required, or pay extra (or get blocked) once they use their allocation.
Billing and usage analytics with forecast usage help customers and YOU stay in control of their AI usage and history.
Embed Real-time calls and call logs into your apps
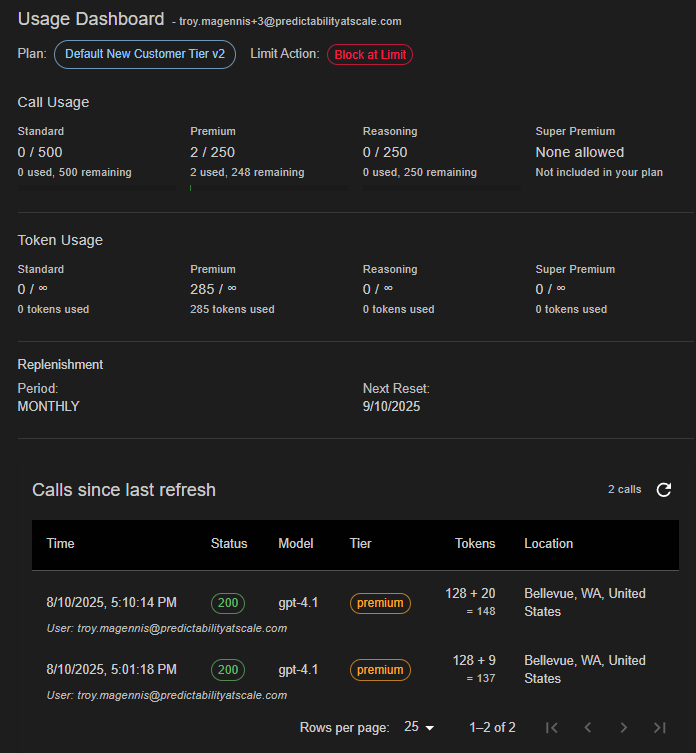
Embeddable Usage and Call Log Widgets
Your customers want to be in control (as do you) of their usage. Create embeddable widgets for you application or website showing the key information customers need to know when to “upgrade” or when they exceed their allocation.
Example embeddable widget giving your customers their usage and call history;
Tip: Embed Call to Actions right in the response. In this example we link to yelp recommendations for any restaurant, and search for hotels. Make your LLM features more useful & convert to revenue!
Add "Tools" through MCP
Now with added MCP
Give your agents tools. MCP connects external tools and data to your agents. For example, you can connect JIRA and ask “What issues are assigned to me in JIRA”, or any of hundreds of servers. The feature is currently for enterprise customers, and contact us if you want to work with us to get your MCP SSE servers added.
Q. What MCP servers do you support? A. We support open SSE servers. Our roadmap is rapidly evolving, and we are adding oAuth and HTTP Streaming transport soon.
Unlock the full potential of your AI chat agents by tapping into real-time analytics of customer interactions. Our platform gives you immediate visibility into the quality, context, and effectiveness of every conversation, helping you make informed decisions to enhance customer experiences.
Empower your teams to iterate, optimize, and scale your AI-driven customer engagement with precise, actionable data at your fingertips.
It's like "Google Analytics for your LLM Chat Agents"
Instant Engagement Insights: Quickly identify which AI interactions resonate with your customers through intuitive thumbs up/down feedback, enabling continuous improvement of your chat agents.
Actionable Conversion Metrics: Measure how effectively your AI chats drive key customer actions, such as purchasing products, initiating contact requests, or escalating conversations to human representatives.
Contextual Response Analysis: Gain deep understanding of customer sentiment and response quality, enabling proactive refinement of your AI agents’ messaging and domain-specific configurations.
User Behavior Tracking: Understand how customers engage with linked actions within chats, helping you optimize your conversational flows to increase conversion rates and user satisfaction.
Comprehensive Monitoring & Reporting: Access detailed reports and visualizations, much like Google Analytics, providing clarity and actionable insights into conversational performance across your entire AI ecosystem.
Get personal: Customer "Memory" and Knowledge Graphs
Customer Memory Capture and Injection
Avoid customers repeating themselves and missing relevant suggestions and upsells. Conversations can be analyzed for key facts, preferences, identity, etc. and these added to that customers “memory.” When they return or continue a conversation, those memories IMPROVE the responses, giving that personal touch often missing from automated AI chat conversation agents. KNOW YOUR CUSTOMER!
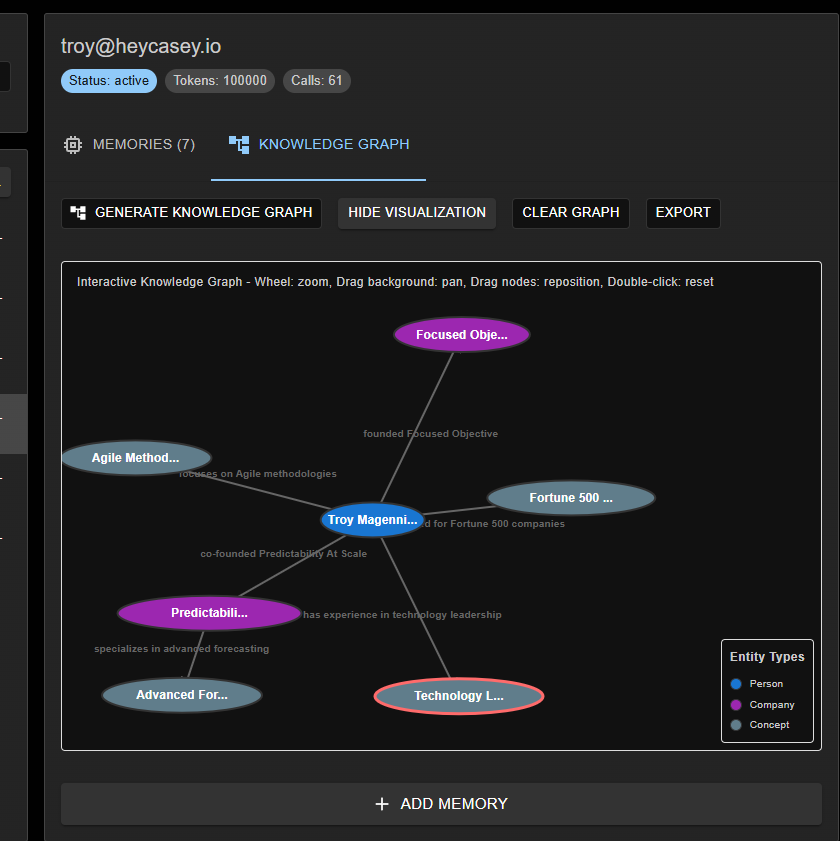
Powerful Knowledge Graphs
Build and understand your customers by summarizing what you know about them into knowledge graphs. These graphs synthesize the who, what and how these relate to each other for deep analysis and understanding. These graphs are created from the memories extracted through conversation or seeded by research (analyzing text or website data or LinkedIn profile as examples).
In this example, a LinkedIn profile was analyzed for memories and knowledge graph. Whenever this user has a conversation from this time forward, the Agents ALREADY KNOW these facts and how they relate to the customer leading to better and responses. Memories can come from prior conversations, or through text analysis of websites or files.
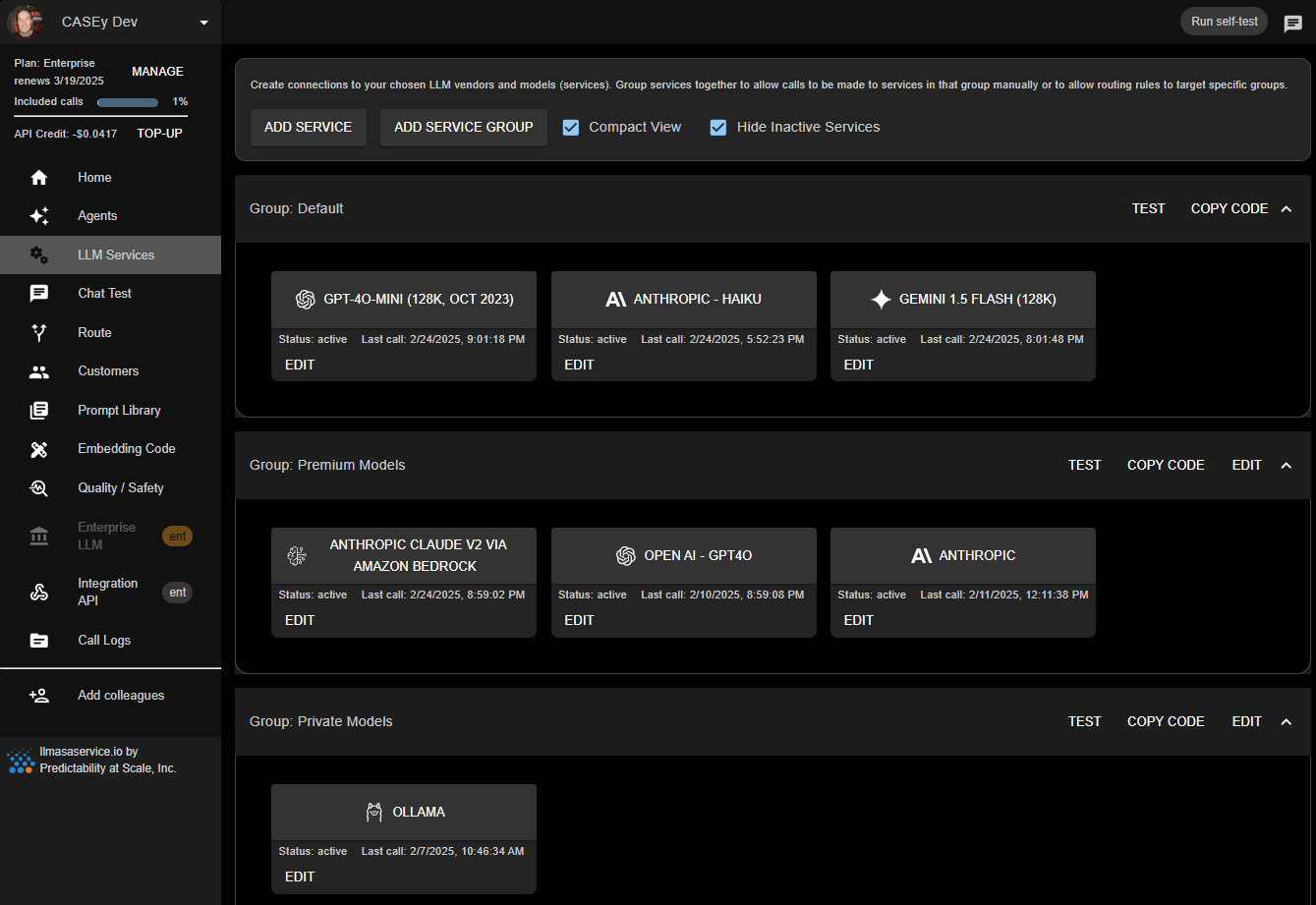
Multiple vendors and models - reliable and convenient
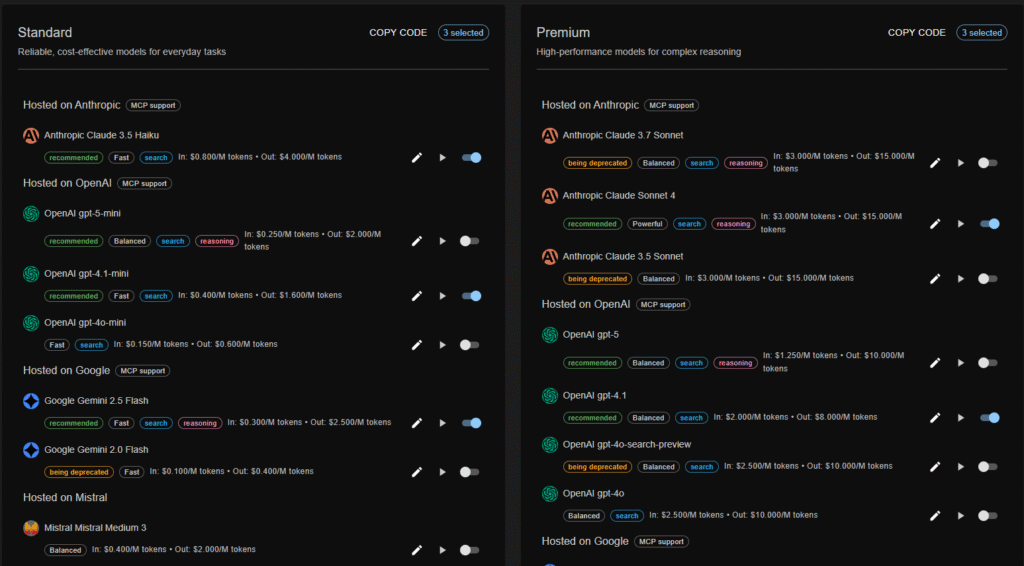
Multiple vendors and models
Avoid vendor or model lock-in, and manage model groups in one place, including API keys. Keep any vendor specific API code and model names OUT of your source code.
New Model Introduction and Sunsetting
There will always be a new and better model. You won’t have to change your code to try them out and make them generally available in your application
Get in touch with us today to pilot LLMasaService.io
You aren’t limited to public models. You can call your own private models, see our 3 minute tutorial video here ->
Our value prop is simple: We handle the hidden features needed to deliver reliable, and valuable LLM features to your customers
Smart Routing - right model at the right price for any prompt
Smart ML Model Routing
Use our pre-trained model for choosing between general or stronger models. Or, you can try a stronger model using code or feedback from customers about prompt quality.
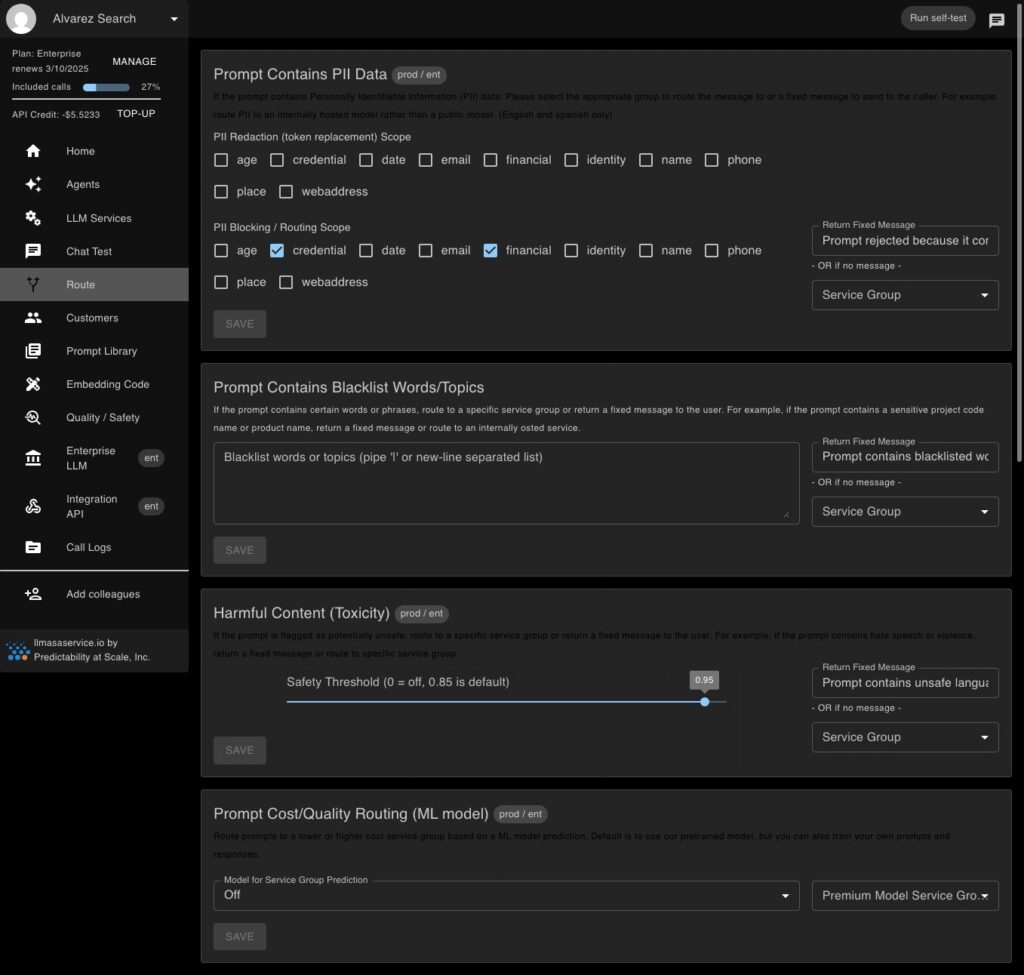
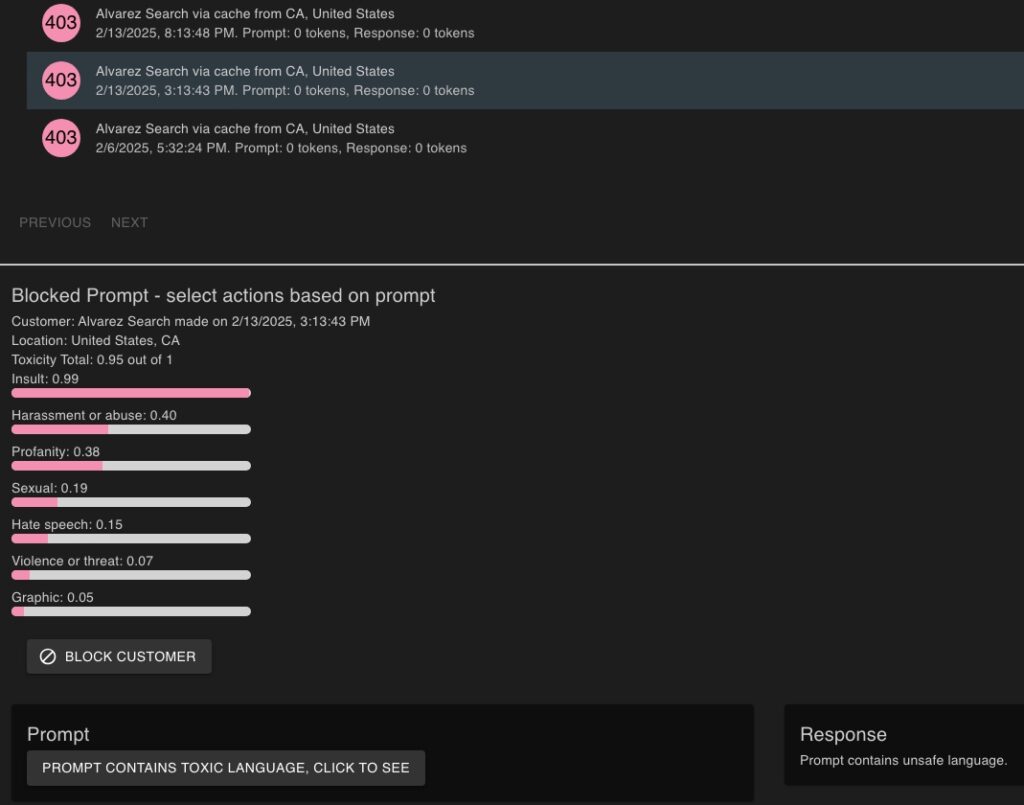
Route or block sensitive or unsafe prompts
Control how prompts get routed when they contain hateful, PII or specific keywords. Options are to route to internal models or to block those prompts.
Get in touch with us today to pilot LLMasaService.io
Log and avoid harmful prompts being accepted. Stop violent, hateful, sexual, profane or graphic prompts before risking a vendor responding inappropriately.
Manage Brand and Policy Instructions
Define your brand and legal policy instructions in one place. These instructions will be injected into EVERY prompt ensuring your responses stay on message.
Visibility, Control, and Security with our Developer Control Panel.
Bring multiple providers online, use the “chaos monkey” to test outage behavior, monitor requests and token usage, set up customer tiers and securely store all your API Keys in one place.
Already thinking about adding LLM features to your application or website? Here is a matrix of features to help you understand the buy versus build decision.